Ejecutar modelos de machine learning en el browser tiene mucho sentido: sin latencia de red, sin datos que salen del dispositivo, sin servidor que mantener. El problema siempre ha sido el rendimiento. Con WebGPU como backend, ese problema mejora de forma significativa.
En este artículo vemos cómo usar TensorFlow.js con el backend WebGPU, qué diferencia de rendimiento supone frente al backend CPU, y qué casos de uso son viables hoy en producción.
TensorFlow.js y sus backends
TensorFlow.js puede ejecutar las mismas operaciones matemáticas usando distintos backends:
| Backend | Ejecuta en | Cuándo usarlo |
|---|---|---|
cpu | CPU (JavaScript puro) | Fallback universal |
wasm | CPU (WebAssembly) | Mejor que CPU puro, sin GPU |
webgl | GPU (WebGL 1/2) | Antes de WebGPU |
webgpu | GPU (WebGPU) | Máximo rendimiento |
El backend webgpu es el más reciente y el más rápido. Usa compute shaders para las operaciones matriciales que son el núcleo de cualquier red neuronal.
Setup
npm install @tensorflow/tfjs @tensorflow/tfjs-backend-webgpu
import * as tf from "@tensorflow/tfjs";
import "@tensorflow/tfjs-backend-webgpu";
async function init() {
await tf.setBackend("webgpu");
await tf.ready();
console.log("Backend activo:", tf.getBackend()); // 'webgpu'
}
Con un fallback robusto:
async function initBestBackend() {
const backends = ["webgpu", "webgl", "wasm", "cpu"];
for (const backend of backends) {
try {
await tf.setBackend(backend);
await tf.ready();
console.log(`Backend: ${tf.getBackend()}`);
return;
} catch {
console.warn(`${backend} no disponible, probando siguiente...`);
}
}
}
Ejemplo: clasificación de imágenes con MobileNet
MobileNet es un modelo ligero para clasificación de imágenes, ideal para empezar.
import * as mobilenet from "@tensorflow-models/mobilenet";
const RUNS = 5;
async function classifyImage(imageElement) {
await initBestBackend();
const model = await mobilenet.load({ version: 2, alpha: 1.0 });
// Primera inferencia: más lenta (compilación de shaders)
const firstStart = performance.now();
await model.classify(imageElement);
const firstMs = performance.now() - firstStart;
// Inferencias posteriores: velocidad de crucero
const times = [];
for (let i = 0; i < RUNS; i++) {
const start = performance.now();
await model.classify(imageElement);
times.push(performance.now() - start);
}
const median = [...times].sort((a, b) => a - b)[Math.floor(RUNS / 2)];
console.log(`Primera inferencia: ${firstMs.toFixed(1)}ms`);
console.log(`Mediana (${RUNS} runs): ${median.toFixed(1)}ms`);
// [{ className: "tabby cat", probability: 0.87 }, ...]
}
El efecto de la primera inferencia
WebGPU compila los shaders la primera vez que ejecuta un modelo. Esto hace que la primera inferencia sea significativamente más lenta. Es importante calentar el modelo antes de medir o de presentar resultados al usuario.
// ❌ Muestra el spinner durante la compilación de shaders
const predictions = await model.classify(image);
showResults(predictions);
// ✅ Calienta en background, responde rápido desde el principio
await model.classify(warmupImage); // imagen pequeña o placeholder
const predictions = await model.classify(image);
showResults(predictions);
Benchmarks: CPU vs WebGPU
Inferencia con MobileNet v2 sobre una imagen 224×224:
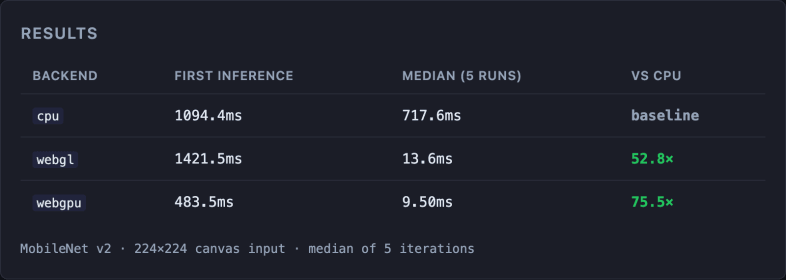
MacBook Air M4, GPU Apple Metal-3. MobileNet v2 · imagen canvas 224×224 · mediana de 5 iteraciones · ejecuta el benchmark en tu dispositivo (código fuente).
La primera inferencia de webgl es más lenta que la de webgpu (1421ms vs 483ms): webgpu compila los shaders de forma más eficiente. En las inferencias posteriores, ambos backends son órdenes de magnitud más rápidos que la CPU, pero webgpu saca ventaja: 9.5ms frente a 13.6ms de webgl, una mejora del 30%.
Para casos de uso en tiempo real (cámara, vídeo), esa diferencia es crítica.
Caso real: detección de poses en tiempo real
Uno de los casos más demandantes es la detección de poses (BlazePose, MoveNet) sobre el stream de la cámara a 30 fps. Con webgl, en muchos dispositivos de gama media no se alcanza la tasa de frames necesaria. Con webgpu, sí.
import * as poseDetection from "@tensorflow-models/pose-detection";
async function startPoseDetection(videoElement, canvasElement) {
await tf.setBackend("webgpu");
await tf.ready();
const detector = await poseDetection.createDetector(
poseDetection.SupportedModels.MoveNet,
{ modelType: poseDetection.movenet.modelType.SINGLEPOSE_THUNDER }
);
const ctx = canvasElement.getContext("2d");
async function detectFrame() {
const poses = await detector.estimatePoses(videoElement);
ctx.clearRect(0, 0, canvasElement.width, canvasElement.height);
ctx.drawImage(videoElement, 0, 0);
for (const pose of poses) {
drawKeypoints(ctx, pose.keypoints); // implementa tu propia función de dibujo
drawSkeleton(ctx, pose.keypoints); // implementa tu propia función de esqueleto
}
requestAnimationFrame(detectFrame);
}
detectFrame();
}
Con webgpu, este loop corre a 25-30 fps en un MacBook Pro. Con cpu, baja a 2-3 fps.
Modelos viables en producción hoy
No todos los modelos son apropiados para el browser, incluso con WebGPU. La limitación es la descarga y el tamaño en memoria.
| Modelo | Tarea | Tamaño | FPS con WebGPU |
|---|---|---|---|
| MobileNet v2 | Clasificación | ~14 MB | ~60 fps |
| MoveNet Lightning | Detección de poses | ~9 MB | ~50 fps |
| BlazeFace | Detección facial | ~0.6 MB | ~60 fps |
| YOLOv8n | Detección de objetos | ~6 MB | ~30 fps |
| Whisper Tiny | Transcripción de audio | ~75 MB | No tiempo real |
Los modelos “nano” y “tiny” están diseñados para inferencia en el edge y son los que mejor funcionan en el browser.
Consideraciones de rendimiento
Memoria GPU compartida
La GPU del dispositivo comparte memoria con el renderizado de la propia página. Modelos grandes pueden generar presión de memoria y afectar al rendimiento visual.
Descarga del modelo
Usar la Cache API para persistir los pesos del modelo entre sesiones y evitar descargas repetidas.
// Cachear el modelo con la Cache API
const CACHE_NAME = "tfjs-models-v1";
async function loadModelWithCache(modelUrl) {
const cache = await caches.open(CACHE_NAME);
const cached = await cache.match(modelUrl);
if (!cached) {
await cache.add(modelUrl);
}
return tf.loadGraphModel(modelUrl);
}
Web Workers
Mover la inferencia a un Worker evita bloquear el hilo principal, aunque con WebGPU hay limitaciones según el navegador.
La serie
- WebGPU: el nuevo motor de rendimiento del navegador
- Procesamiento de imágenes en el browser con WebGPU
- ML en el browser con WebGPU — estás aquí
- Edición de vídeo en el browser con WebGPU: efectos en tiempo real frame a frame.
Conclusión
WebGPU hace que el ML en el browser pase de ser una curiosidad a algo usable en producción para modelos ligeros. La combinación TensorFlow.js + backend WebGPU con fallback a WebGL o WASM cubre la mayoría de navegadores modernos.
El caso de uso más claro: cualquier funcionalidad que necesite procesar cámara o imágenes del usuario en tiempo real sin enviar datos al servidor. Privacidad y rendimiento a la vez.
En el próximo artículo cerramos la serie con el caso más ambicioso: edición de vídeo en el browser con WebGPU.